How to use the PigeonSuperModel DataSet
Contents
How to use the PigeonSuperModel DataSet¶
Download this notebook in the upper right corner as .ipynb file and start it from within your DeepLabCut environment. If you need to install DeepLabCut first, please check here.
This notebook will show you how to create a pretrained project with the PigeonSuperModel and how to download and merge the pre-labeled PigeonSuperModel dataset to increase your own training data:
Create a new PigeonSuperModel Project
Extract new Frames
Label your own Data
Merge PigeonSuperModel DataSet
Re-Train the PigeonSuperModel
Evaluate your new PigeonSuperModel
Contribute to PigeonSuperModel.com
import os
import deeplabcut
from tkinter import filedialog
print(f'Using DeepLabCut version: {deeplabcut.__version__}')
Create a new project¶
See Notebook before
video_path = r'F:\PigeonSuperModel_local\ForAnalysisVideoData\StopSignal'
video_list = os.listdir(video_path)
projectpath = r'F:\PigeonSuperModel_local\DeepLabCutModels'
def monkeypatch():
'''
This function locates a file named 'pose_estimation_tensorflow/models/pretrained/pretrained_model_urls.yaml' in your local DeepLabCut
installation and adds the new URLs below to reach the PigeonSUperModel repository.
In a last step, the names of the PigeonSuperModels are added to the 'modelzoo.py' Modeloptions as valid model names.
'''
from deeplabcut.create_project import modelzoo
# locate the `pretrained_model_urls.yaml` file in your local DeepLabCut installation (hardcoded based on deeplabcut dir structure)
neturls_path = os.path.join(deeplabcut.auxiliaryfunctions.get_deeplabcut_path(), 'pose_estimation_tensorflow', 'models', 'pretrained', 'pretrained_model_urls.yaml')
edits = {'PigeonSuperModel_resnet_50': 'https://gitlab.ruhr-uni-bochum.de/ikn/pigeonsupermodel/-/raw/main/models/DeepLabCut/DLC_PigeonSuperModel_01_resnet_50_iteration-2_shuffle-3.tar.gz',
'PigeonSuperModel_resnet_101': 'https://gitlab.ruhr-uni-bochum.de/ikn/pigeonsupermodel/-/raw/main/models/DeepLabCut/DLC_PigeonSuperModel_01_resnet_101_iteration-2_shuffle-4.tar.gz',
'PigeonSuperModel_resnet_152': 'https://gitlab.ruhr-uni-bochum.de/ikn/pigeonsupermodel/-/raw/main/models/DeepLabCut/DLC_PigeonSuperModel_01_resnet_152_iteration-2_shuffle-5.tar.gz'}
# add new model to the neturls file
deeplabcut.auxiliaryfunctions.edit_config(neturls_path, edits)
# add new model to locally loaded Modeloptions from modelzoo.py
modelzoo.Modeloptions.extend(['PigeonSuperModel_resnet_50', 'PigeonSuperModel_resnet_101', 'PigeonSuperModel_resnet_152'])
# you may need admin rights on your computer to edit the files above
monkeypatch()
def create_dummy_videos(target_dir):
import urllib.request
import cv2
# create dummy video
logolink = 'https://gitlab.ruhr-uni-bochum.de/ikn/pigeonsupermodel/-/raw/main/PigeonSuperModel.png?inline=false'
logo = os.path.join(target_dir, 'logo.png')
urllib.request.urlretrieve(logolink, logo);
dummyvideo = os.path.join(target_dir, 'logo.mp4')
img_array = []
for i in range(20):
img = cv2.imread(logo)
height, width, layers = img.shape
img_array.append(img)
os.remove(logo)
out = cv2.VideoWriter(dummyvideo, cv2.VideoWriter_fourcc(*'mp4v'), 20, (width, height))
for i in range(len(img_array)):
out.write(img_array[i])
out.release()
return dummyvideo
# create dummy video to use copy=True
video_path = create_dummy_videos(projectpath)
# create pre-trained model from PigeonSuperModel
config_path, _ = deeplabcut.create_pretrained_project(
'StopSignal',
'PigeonSuperModel',
[video_path],
videotype='mp4',
copy_videos=True,
working_directory=projectpath,
model='PigeonSuperModel_resnet_50',
analyzevideo=False,
filtered=False,
createlabeledvideo=False,
)
os.remove(video_path)
sign = {'PigeonSuperModel': f'The pretrained PigeonSuperModel was added to this project. (C) PigeonSuperModel.com'}
deeplabcut.auxiliaryfunctions.edit_config(config_path, sign)
Copying the videos may take very long, and creating hyperlinks does not always work on windows. Alternatively,
we can add the video paths to the config.yaml file while leaving our video data on a separate disk.
# patch: add video links to config.yaml
def add_videopaths(config, video_list):
from pathlib import Path
from deeplabcut.utils.auxfun_videos import VideoReader
videos = video_list
original_video_sets = deeplabcut.auxiliaryfunctions.read_config(config)['video_sets']
projectpath = deeplabcut.auxiliaryfunctions.read_config(config)['project_path']
# create new dict for video_sets
video_sets = {}
for video in videos:
print(f'Adding video: {video}')
try:
rel_video_path = str(Path.resolve(Path(video)))
vid = VideoReader(rel_video_path)
video_sets[rel_video_path] = {"crop": ", ".join(map(str, vid.get_bbox()))}
except:
print(f'Could not read video, writing fake frame dimensions ...')
rel_video_path = str(Path.resolve(Path(video)))
video_sets[rel_video_path] = {"crop": ", ".join(map(str, [0, 1920, 0, 1080]))} # how bad is this
# create labels directory
labeldir = os.path.basename(video).split('.')[0]
if os.path.isdir(os.path.join(projectpath,'labeled-data', labeldir)):
print('Labels directory already exists!')
else:
print(f'Creating directoy: {labeldir}')
os.mkdir(os.path.join(projectpath,'labeled-data', labeldir))
# expand existing video_sets
if original_video_sets is None:
new_video_sets = video_sets
else:
new_video_sets = {**original_video_sets, **video_sets}
# add videos to project
edit = {'video_sets': new_video_sets}
deeplabcut.auxiliaryfunctions.edit_config(config, edit);
return
# add video paths
#video_list = filedialog.askopenfilenames(title = 'Choose video paths to include to your project')
add_videopaths(config_path, video_list)
Alternatively you can just load a previously created model:
# load new project (see Notebook before to create a new project)
config = filedialog.askopenfilenames(title='Choose the config.yaml file of your DeepLabCut project:')
config_path = config[0]
print(f'Using project path: {config_path}')
Optional: Create 3D project to match synchronous frames¶
# create 3d config
config_3d = deeplabcut.create_new_project_3d('StopSignal','3D',num_cameras = 2, working_directory=deeplabcut.auxiliaryfunctions.read_config(config_path)['project_path'])
# change settings
edits = {'camera_names': ['camR', 'camL']}
deeplabcut.auxiliaryfunctions.edit_config(config_3d, edits);
config_3d = r'F:\PigeonSuperModel_local\DeepLabCutModels\StopSignal-PigeonSuperModel-2022-07-08\StopSignal-3D-2022-07-08-3d\config.yaml'
Extract New Frames¶
# select videos for primary camera
video_sets = deeplabcut.auxiliaryfunctions.read_config(config_path)['video_sets']
primary_camera = deeplabcut.auxiliaryfunctions.read_config(config_3d)['camera_names'][0]
videos_primary = [str(video) for video in video_sets if primary_camera in video]
# change the number of frames to extract
edits = {'numframes2pick': 10}
# write changes to config.yaml
deeplabcut.auxiliaryfunctions.edit_config(config_path, edits);
# Extract frames
# Note: videos_list parameter is only available since dlc==2.2.1
deeplabcut.extract_frames(config_path, mode="automatic", algo="uniform", userfeedback = False, videos_list = videos_primary)
Optional: Extract Matching Frames in 3D projects¶
def patch_mp4toavi(config):
import cv2
import shutil
# get videos from config.yaml
video_sets = deeplabcut.auxiliaryfunctions.read_config(config)['video_sets'].keys()
projectpath = deeplabcut.auxiliaryfunctions.read_config(config)['project_path']
original_videos = [video for video in video_sets]
# patch videos for matched frame extraction se here: https://github.com/DeepLabCut/DeepLabCut/issues/1211#issuecomment-1177537516
patched_videos = [os.path.join(projectpath, 'videos', os.path.basename(video).split('.')[0] + '.avi') for video in original_videos]
# change video extension and move
for old, new in zip(original_videos, patched_videos):
# test and close videos
cap = cv2.VideoCapture(video)
while(cap.isOpened()):
# read first frame
cap.read()
# break after first frame
break
cap.release()
# Closes all the frames
cv2.destroyAllWindows()
# rename
if os.path.isfile(new):
print(f'File {new} already exists')
else:
shutil.move(old, new)
#os.rename(old, new)
print(f'Video: {old} changed to {new}')
return original_videos, patched_videos
def patch_reverse_mp4toavi(original_videos, patched_videos):
import shutil
for old, new in zip(original_videos, patched_videos):
# reverse video patch to original
shutil.move(new, old)
print(f'Video: {new} reversed to {old}')
return
# patch videos for matched frames see here: https://github.com/DeepLabCut/DeepLabCut/issues/1211#issuecomment-1177537516
original_videos, patched_videos = patch_mp4toavi(config_path)
# Overwrite matched synchronous frames with mode="match" and config3d file
deeplabcut.extract_frames(config_path, mode="match", config3d=config_3d, extracted_cam=0, userfeedback = False)
# reverse patched videos
patch_reverse_mp4toavi(original_videos, patched_videos)
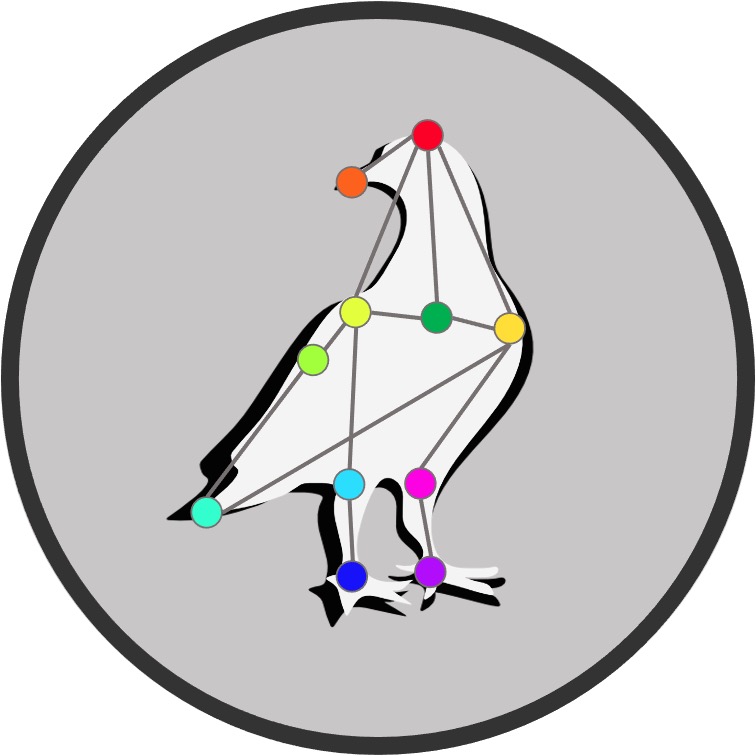
Label your own Data first¶
# manually label frames
deeplabcut.label_frames(config_path)
# check labels
deeplabcut.check_labels(config_path)
Merge the PigeonSuperModel DataSet¶
How to use the PigeonSuperModel Dataset. Once you have your own DeepLabCut project for single Pigeon tracking, why not spiking your dataset with an extra 1000 pre-labeled frames? The cells below will guide you through this process.
# make a single function
def merge_psm_dataset(config):
import urllib.request
import tarfile
import pandas as pd
from pathlib import Path
# read config.yaml
target_dir = deeplabcut.auxiliaryfunctions.read_config(config)['project_path']
scorer = deeplabcut.auxiliaryfunctions.read_config(config)['scorer']
original_video_sets = deeplabcut.auxiliaryfunctions.read_config(config)['video_sets']
# download
print('Downloading DataSet from: gitlab.ruhr-uni-bochum.de/ikn/pigeonsupermodel ...')
dataset_url = 'https://gitlab.ruhr-uni-bochum.de/ikn/pigeonsupermodel/-/archive/main/pigeonsupermodel-main.tar.gz?path=dataset/DeepLabCut/labeled-data'
filename, _ = urllib.request.urlretrieve(dataset_url)
statement = 'The PigeonSuperModel Dataset was added to this project to increase the number of labeled frames. (C) PigeonSuperModel.com'
# Extract .tar
print(f'Extracting tar file to: {target_dir} ...')
with tarfile.open(filename, mode="r:gz") as tar:
tar.extractall(target_dir)
dataset_path = [os.path.join(target_dir, path) for path in os.listdir(target_dir) if 'pigeonsupermodel' in path][0]
# scrap pre-labeled dataset
print(f'Merging Dataset to: {os.path.join(target_dir, "labeled-data")} ...')
for root, dirs, files in os.walk(dataset_path):
for f in files:
if '.h5' in f:
h5file = os.path.join(root, f)
# rename scorer in .h5
df = pd.read_hdf(h5file)
df.columns = df.columns.set_levels([scorer], level=0)
# rename .h5 file
rename = os.path.join(root, f'CollectedData_{scorer}.h5')
df.to_hdf(rename, key = "df_with_missing", mode="w")
# move frame set to labeled-data
src = root
dst = os.path.join(target_dir, 'labeled-data', os.path.basename(root))
os.rename(src, dst)
# add dummy videopaths to config.yaml files
print('Adding video paths to "video_sets" in config.yaml ...')
framesets = os.listdir(os.path.join(target_dir, 'labeled-data'))
videos = [os.path.join(target_dir, 'videos',frameset+'.avi') for frameset in framesets]
# create new dict for video_sets
video_sets = {}
for video in videos:
rel_video_path = str(Path.resolve(Path(video)))
video_sets[rel_video_path] = {"crop": ", ".join(map(str, [0, 1920, 0, 1080]))} # how bad is this?
# expand existing video_sets
if original_video_sets is None:
new_video_sets = video_sets
else:
new_video_sets = {**original_video_sets, **video_sets}
# add video paths to project
edit = {'video_sets': new_video_sets,
'PigeonSuperModel_data': statement}
deeplabcut.auxiliaryfunctions.edit_config(config, edit);
print('The PigeonSuperModel Dataset has been successfully merged to your project! Enjoy')
return
merge_psm_dataset(config_path)
Now you are ready to create a training dataset and train your own model
Re-Train the PigeonSuperModel¶
# create training set
deeplabcut.create_training_dataset(config_path, num_shuffles=1, net_type='resnet_50', augmenter_type='imgaug')
# find pose_cfg.yaml
for root, dirs, files in os.walk(deeplabcut.auxiliaryfunctions.read_config(config)['project_path']):
for file in files:
if 'pose_cfg.yaml' in file:
pose_cfg = os.path.join(root, file)
pose_cfg
# edit relevant training parameters
edits = {'multi_step': [[0.005, 10000], [0.02, 430000], [0.002, 730000], [0.001, 1030000]], # change this to train over 1M iterations
'init_weights': path_to_lastsnapshot, # change this to use pre-trained model
'max_input_size': 2000, # change this to largest frame dimension in dataset
'global_scale': 0.4, # change this to rescale frames to reduce GPU load
}
deeplabcut.auxiliaryfunctions.edit_config(pose_cfg, edits)
# train
deeplabcut.train_network(config_path, max_snapshots_to_keep=None, displayiters=1000, saveiters=10000, maxiters=1000000, allow_growth=True)
Evaluate your new PigeonSuperModel¶
# change config.yaml file to evaluate all snapshots
edits = {'snapshotindex': 'all'}
deeplabcut.auxiliaryfunctions.edit_config(config_path, edits)
# evaluate snapshots
deeplabcut.evaluate_network(config_path, plotting=False)
def check_evaluation_results(config):
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# read config
config = deeplabcut.auxiliaryfunctions.read_config(config)
projectpath = config['project_path']
iteration = config['iteration']
modelname = config['Task']
pcutoff = config['pcutoff']
videores = list(config['video_sets'].items())[0][1]['crop'].split(',')[1:4:2]
# read evaluation results
evals = os.path.join(projectpath, 'evaluation-results', f'iteration-{iteration}', 'CombinedEvaluation-results.csv')
df = pd.read_csv(evals)
evaluation_results = df.loc[:, ~df.columns.isin(['Unnamed: 0', '%Training dataset', 'Shuffle number', 'p-cutoff used'])]
evaluation_results
# plot evaluation results
evaluation_results.plot.line(x = 'Training iterations:',
title = f"Evaluation results of DLC Model {modelname}",
ylabel = f"Pixel Error in {videores[0]}:{videores[1]} resolution frames",
xlabel = f"Training Iterations in DLC [p-cutoff = {pcutoff}]",
xticks = np.arange(0, 1000001, 40000),
rot = 45, figsize = (15,10))
plt.ticklabel_format(axis='both', style='plain')
plt.show()
# check evaluation results
return evaluation_results
# show evaluation results
check_evaluation_results(config_path)
# export model
deeplabcut.export_model(config_path, shuffle=0, iteration=0, snapshotindex=-1, make_tar=True, modelprefix='')
Contribute to PigeonSuperModel.com¶
Do you have an improved version of the PigeonSuperModel?
Share your labeled data and your new trained model with us to contribute to the PigeonSuperModel.com.
Get in touch at Guillermo.HidalgoGadea@ruhr-uni-bochum.de or at GuillermoHidalgoGadea.com